Code Repo
https://github.com/hy2632/Efficient-Frontier
https://github.com/hy2632/Efficient-Frontier
Systematic Trading P41 提及,做空 跨式期权(Straddle) 是一种负偏的交易策略。
Barings 的 Nick Leeson 在1995年 short straddle 损失 $1B。 How Did Nick Leeson Contribute To The Fall of Barings Bank?
使用场景:预测股价有大幅波动,但不知道方向。当价格波动大时获利。但也要考虑到在出现可能的价格波动时期权价格也会上升。

In Robert Carver's book "Systematic Trading", he compared the two mindsets of trading: "Early Profit Taker" and "Early Loss Taker". The previous one is our mankind's "flawed instinction" and the latter one is believed to outperform the previous one.
This notebook implements the argument and verifies it through different examples.
Some of the parameters in the method is at your own discretion. Stocks and futures might take values to different orders of magnitude w.r.t. the "tolerance_lo", let alone the fact that everyone has his own extent of tolerance.
Hua Yao, UNI:hy2632
Here we propose an estimator using antithetic sampling for variance reduction.
State, Action
Policy: Deterministic / Randomized
Function \(F: \mathbb{R}^d \to \mathbb{R}\), reward from vector to scalar.
Hua Yao, UNI:hy2632
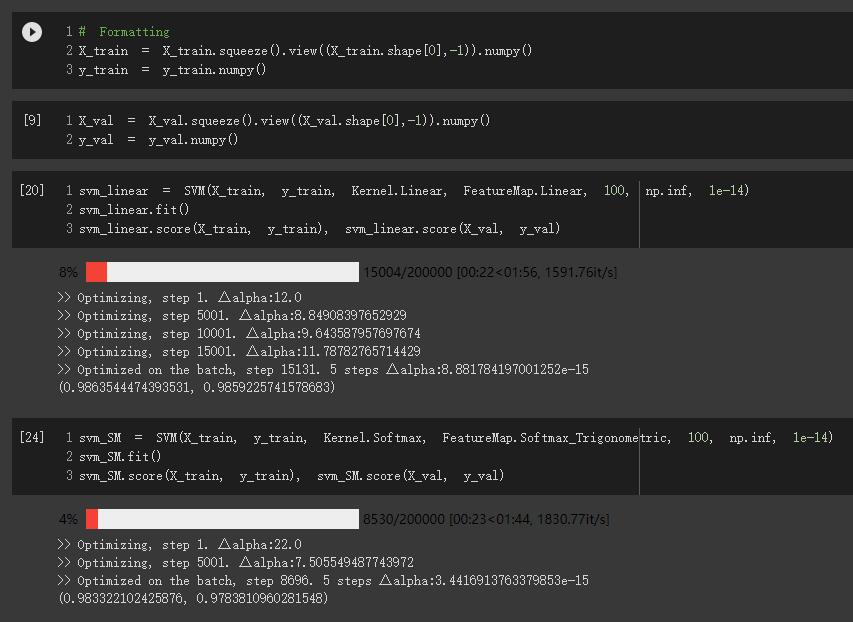
Used dual SVM
Did not consider regularization, a.k.a. set \(C=\infty\), because this problem (binary classification between 0/9) should be separable, and the representation of \(b\) becomes nasty with regularization.
Used the SMO (sequential minimal optimization) algorithm. During optimization, within each iteration, randomly select \(\alpha_1, \alpha_2\), optimize the QP w.r.t. \(\alpha_2\) and update \(\alpha_1\) accordingly. Added constraint \(\alpha_2 \geq 0\) to the \(\alpha_2\) optimizer. This does not constrain \(\alpha_1\geq 0\) directly. However, with the randomization within each iteration, \(\alpha_i \geq 0\) is satisfied when the whole optimzation over \(\alpha\) finally converges.
Provide 2 options: Linear Kernel (baseline SVM) or Softmax kernel
\[K_{SM}(x, y) = \exp{x^\top y}\]
To avoid explosion on scale, normalized the input \(x\).
Included the trigonometric feature map \(\phi(x)\) of the softmax kernel for calculating \(b\), (not for \(w\) because when making prediction, we use kernel function instead of \(w^\top \phi\)).
Use exact kernel instead of approximating kernel with random feature map, because softmax's dimensionality is infinite. Directly compute the exponential in numpy is more efficient.
The prediction comes like this (vectorized version):
\[y_{new} = K(X_{new}, X)\cdot (\alpha * y) + b\]
Note that b is broadcasted to \(n'\) new data points. \(K(X_{new}, X)\) is \(n' \times n\) kernel matrix. \(\alpha*y\) means the elementwise product of two vectors.
SVM is expensive when \(n\) is large. Here in practice, we trained on a small batch (default=64). The randomness here influences the performance.
Have a few trial runs to get the model with best prediction on the training data. Then it should give good prediction on the validation data. You might also need to tune the hyperparameters a little bit, like batch_size and tol.
1 | Machine Learning |
两者区别在于 \(w\) 是否被标准化。效用边际会受到参数scale的影响。如果标准化了则两者等效。
经过转换,问题变为一个QP问题,可以用一般优化器优化。
Primal:
1 | import numpy as np |
KKT, Lagrangian
\[L(w, b, \alpha, \beta) = f(w,b) + \sum_{i=1}^{N}{\alpha_ig_i(w,b)} + \sum_{i=1}^{N}{\beta_ih_i(w,b)}\]
\[\theta(w,b) = \max_{\alpha, \beta} L(w, b, \alpha, \beta) \]
\[\theta(w,b) = \begin{cases} f(w,b) \text{\: if feasible} \\ \infty \text{\: otherwise} \end{cases}\]
Hua Yao, UNI:hy2632
The input RGB- image has 3 channels. Apply Conv2D to each channel to get 3 feature maps.
When there's no padding, the shape of 3 feature maps are \(125\times125\).