1 Problem 1: Softmax-kernel approximators [50 points]
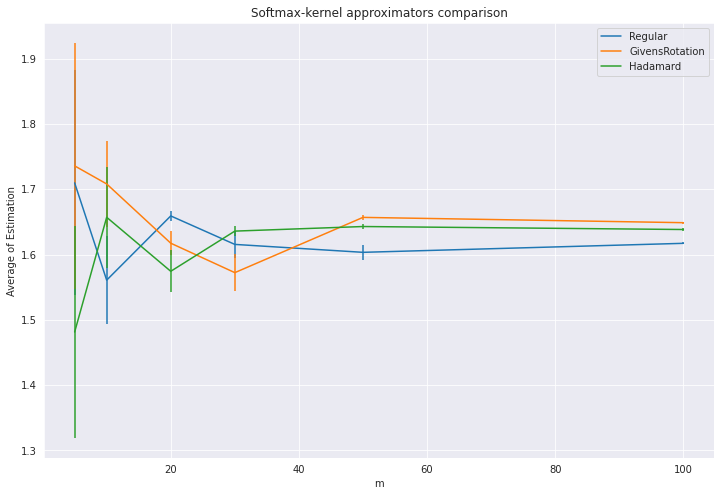
The goal of this task is to test different random feature map based estimators of the softmax-kernel. Choose two feature vectors \(x, y \in \mathbb{R}^{20}\) of unit \(L_2\)-norm and with angle \(\frac{π}{3}\) between them. Consider three estimators of the value of the softmax-kernel in these points: the regular one using independent sin/cos-random features (leveraging random feature maps for the Gaussian kernel) and its two modifications: the one using Givens random rotations and the one applying random Hadamard matrices (with three HD-blocks). Describe in detail each estimator. Then for the number of random projections \(m = 5, 10, 20, 30, 50, 100\) and each estimator, compute its value as an average over \(s = 10\) independent trials. Propose how to use those trials to compute empirical mean squared error for each estimator. Prepare plots where on \(x\)-axis you put the number of random projections m used and on the \(y\)-axis the average value of the estimator. Show also computed mean squared error in the form of the error-bars. Remark: If \(m > d\) the orthogonal trick can be still applied by constructing independent ensembles of samples such that within each ensemble samples are exactly orthogonal.
Problem 2 Softmax-kernel is positive semidefinite [30 points]
for any \(N>0\), any set of feature vectors \(\chi = \{x_1, ..., x_N\}\subseteq \mathbb{R}^d\), matrix \(\kappa(X) := [K(x_i, x_j)]_{i,j=1,...,N} \in \mathbb{R}^{N\times N}\) and any vector \(v \in \mathbb{R}^{N}\). Show that softmax-kernel is PSD.
Lemma1: \(X^TX \in \mathbb{R}^N and \ XX^T \in \mathbb{R}^d\) are PSD
Proof:
\[v^T(X^TX)v = (Xv)^T(Xv) = y^Ty \geq 0\]
\[v \in \mathbb{R}^{N}\]
\[y = Xv \in \mathbb{R}^{d}\]
Similarly, $XX^T $ is PSD
Lemma2: \((X^TX)^k \ and \ (XX^T)^k, k=0,1,2,...\) are PSD.
Proof:
For \(k=0\), obviously \(I\) is PSD.
From above, this holds when \(k=1\). Use mathematical induction, if this is true for \(k=n-1\), then for \(k=n\)\[ v^T(X^TX)^{n}v = (Xv)^T(XX^T)^{n-1}(Xv) = y^T(XX^T)^{n-1}y \geq 0\]\[ v\in \mathbb{R}^N, y = Xv \in \mathbb{R}^d\]\[ u^T(XX^T)^{n}u = (X^Tu)^T(X^TX)^{n-1}(X^Tu) = z^T(X^TX)^{n-1}z \geq 0,\ z\in \mathbb{R}^N \]\[ u\in \mathbb{R}^d, z=X^Tu\in \mathbb{R}^N\]
Therefore this holds for arbitrary \(k \in \{0,1,2,3...\}\).
Lemma3: Matrix exponential
The exponential of a \(N\times N\) matrix \(X\) is: \[e^{X} = \sum_{k=0}^{\infty}{\frac{1}{k!}X^k}\]
import numpy as np import math from sklearn.metrics import mean_squared_error import matplotlib.pyplot as plt import os import random import pandas as pd import seaborn as sns from tqdm import tqdm import datetime from scipy.stats import norm from scipy.spatial.transform import Rotation as R import scipy as sp
Problem 1: Softmax-kernel approximators [50 points]
Choose two feature vectors \(x, y \in \mathbb{R}^{20}\) of unit \(L_2\)-norm and with angle \(\frac{π}{3}\) between them.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
defgenerateXY(d = 20): # init X x = np.array([1] + [0]*(d-1)) y = np.array([0.5, 3**0.5/2] + [0]*(d-2))
# Orthogonal Matrix Q A = np.random.normal(0, 1, (d,d)) Q, _ = np.linalg.qr(A, mode = 'complete')
# x^Ty=0.5 => (Qx)^T(Qy)=0.5, where Q is orthogonal x = np.matmul(Q, x) y = np.matmul(Q, y) return x,y
caculate the norms of each row(\(|w_i|^2\sim \chi^2(d)\))
Map through \(G\)'s \(m\) rows and orthogonalize \(G\)'s each \(d\times d\) block(or the remainder part \((m\%d) \times d\))
Renormalize the orthogonalized matrix with its original row norms. \[ \phi_{SM}(x) = e^{\frac{||x||^2}{2}} \frac{1}{\sqrt{m}} \begin{bmatrix}\cos(w_1^Tx)\\...\\\cos(w_m^Tx)\\\sin(w_1^Tx)\\...\\\sin(w_m^Tx) \end{bmatrix} \]
Calculate \(\phi(x)\) and \(\phi(y)\), and thus \(\phi(x)^T\phi(y)\)
Generate several such \(G_{ort} \in \mathbb{R}^{d'\times d'}\) and concatenate to get \(G_{ort} \in \mathbb{R}^{m\times d'}\)
Apply the softmax random feature function \(\phi_{SM}\) like the regular one
Then for the number of random projections \(m = 5, 10, 20, 30, 50, 100\) and each estimator, compute its value as an average over \(s = 10\) independent trials.
defgram_schmidt_columns(X): Q, R = np.linalg.qr(X) return Q
deforthgonalize(V): N = V.shape[0] d = V.shape[1] turns = int(N/d) remainder = N%d #V = np.random.normal(size=[(turns+1)*d, d]) #V = np.random.normal(size =[N, d]) #print(V.shape) V_ = np.zeros_like(V) for i in range(turns): v = gram_schmidt_columns(V[i*d:(i+1)*d, :].T).T V_[i*d:(i+1)*d, :] = v if remainder != 0: V_[turns*d:,:] = gram_schmidt_columns(V[turns*d:,:].T).T return V_ defgenerateGMatrix(m = 5, d = 20) -> np.array: G = np.random.normal(0,1, (m,d)) # Renormalize norms = np.linalg.norm(G, axis=1).reshape([m,1]) return orthgonalize(G) * norms
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
# Softmax with sin/cos random features defbaseline_SM(x, G, m): """Calculate the result of baseline random feature mapping Parameters ---------- x: array, dimension = d The data point to input to the baseline mapping G: matrix, dimension = m*d The matrix in the baseline random feature mapping m: integer The number of dimension that we want to reduce to """ left = np.cos(np.dot(G, x).astype(np.float32)) right = np.sin(np.dot(G, x).astype(np.float32)) return np.exp( (np.linalg.norm(x))**2 / 2) * ((1/m)**0.5) * np.append(left, right)
1 2 3 4 5 6 7 8 9
defbaseline_SM_approximation(x, y, m, d=20, s=10): sum = 0 for i in range(s): G = generateGMatrix(m=m, d=d) phi_x = baseline_SM(x, G, m) phi_y = baseline_SM(y, G, m) xTy = np.dot(phi_x, phi_y) sum += xTy return sum / s
1 2 3
arr_m = [5, 10, 20, 30, 50, 100] arr_estimation = [baseline_SM_approximation(x, y, i, 20, 10) for i in arr_m] arr_estimation
The idea of Orthogonal Random Features (ORF) is to impose orthogonality on the matrix on the linear transformation matrix \(G\). Note that one cannot achieve unbiased kernel estimation by simply replacing \(G\) by an orthogonal matrix, since the norms of the rows of \(G\) follow the -distribution, while rows of an orthogonal matrix have the unit norm. The linear transformation matrix of ORF has the following form \[W_{ORF} = \frac{1}{\sigma}
SQ\] where \(Q\) is a uniformly distributed random orthogonal matrix. The set of rows of \(Q\) forms a bases in \(R^d\). \(S\) is a diagonal matrix, with diagonal entries sampled i.i.d. from the \(\chi\)-distribution
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
defgenerateGiv(d): Giv = np.identity(d) i = np.random.randint(0, d-1) j = np.random.randint(i+1, d) theta = np.random.uniform(0, 2*np.pi) c = np.cos(theta) s = np.sin(theta) Giv[i,i] = c Giv[j,j] = c Giv[i,j] = s Giv[j, i] = -s return Giv
defGivens_generateGort_dd(d): k = int(d * np.log(d)) Gort_dd = generateGiv(d) for i in range(k-1): Gort_dd = np.matmul(Gort_dd, generateGiv(d)) return np.matmul(generateS(d), Gort_dd)
1 2 3 4 5 6 7 8
defGivens_generateGort_md(m, d): arr_Gort_dd = [] for i in range(m//d + 1): arr_Gort_dd.append(Givens_generateGort_dd(d)) # (m//d+1, d, d) Gort_md = np.concatenate(arr_Gort_dd, axis=0) Gort_md = Gort_md[:m, :]
return Gort_md
1 2 3 4 5 6 7 8 9
defGivensRandomRotations_SM_approximation(x, y, m, d=20, s=10): sum = 0 for i in range(s): G = Givens_generateGort_md(m,20) phi_x = baseline_SM(x, G, m) phi_y = baseline_SM(y, G, m) xTy = np.dot(phi_x, phi_y) sum += xTy return sum / s
1 2 3
arr_m = [5, 10, 20, 30, 50, 100] arr_estimation = [GivensRandomRotations_SM_approximation(x, y, i, 20, 10) for i in arr_m] arr_estimation
# Uncomment to get Structured Orthogonal Random Features (SORF) solution
defHadamard_generateGort_dd(d): t = np.ceil(np.log2(d)).astype(int) d_ = 2**t # H = normalized_Hadamard(t) H = Hadamard(t) Gort_dd = np.identity(d_) for i in range(3): # Gort_dd = np.matmul(Gort_dd ,np.matmul(H, generateDi(d_))) Gort_dd = np.matmul(Gort_dd ,np.matmul(1 / np.sqrt(d_) * H, generateDi(d_))) # return np.sqrt(d_)*Gort_dd return np.matmul(generateS(d_), Gort_dd)
defHadamard_generateGort_md(m, d): t = np.floor(np.log2(d)).astype(int) + 1 d_ = 2**t arr_Gort_dd = [] for i in range(m//d_ + 1): arr_Gort_dd.append(Hadamard_generateGort_dd(d)) Gort_md = np.concatenate(arr_Gort_dd, axis=0) Gort_md = Gort_md[:m, :]
return Gort_md
1 2 3 4 5 6 7 8 9 10 11 12
defHadamard_SM_approximation(x, y, m, d=20, s=10): sum = 0 for i in range(s): G = Hadamard_generateGort_md(m,20) d_ = G.shape[1] x_padded = np.pad(x, (0, d_-d)) y_padded = np.pad(y, (0, d_-d)) phi_x = baseline_SM(x_padded, G, m) phi_y = baseline_SM(y_padded, G, m) xTy = np.dot(phi_x, phi_y) sum += xTy return sum / s
1 2 3
arr_m = [5, 10, 20, 30, 50, 100] arr_estimation = [Hadamard_SM_approximation(x, y, i, 20, 10) for i in arr_m] arr_estimation
# for e in tqdm(range(episode), position=0, leave=True): # x, y = generateXY(20) # true_value = np.exp(0.5) # list_of_samples.append((x, y))
for n in range(len(arr_m)): mse_m = [] m = arr_m[n] for e in tqdm(range(episode), position=0, leave=True): # x = list_of_samples[e][0] # y = list_of_samples[e][1] for i in range(epoch): np.random.seed() estimation[n, e, i] = SM_approximation(x, y, m, d=20, s=1)
Prepare plots where on x-axis you put the number of random projections m used and on the y-axis the average value of the estimator. Show also computed mean squared error in the form of the error-bars